It all started with a performance problem I could not ignore any longer...
The Problem
I've been building an application that deals with displaying live data. I decided to use polling instead of more complex solutions like WebSockets or server-sent events since the data I needed was updated relatively infrequently. I had 4 endpoints being polled all in different times but all within 10 seconds averaging to about 1.2 API calls per second per user and the system handled this load just fine!
I knew however that issues are bound to happen. As the user count increases, this polling strategy becomes a serious liability.
My backend hosted on a single t2.micro EC2 instance running a FastAPI application behind a nginx reverse proxy isn't going to keep up for long.
Not only does it need to handle the constant polling traffic, but it also supports other critical functions like user logins and various core features of the application.
The instance’s limited CPU and memory will start to show strain quickly, as the server begins receiving a high volume of redundant requests, since users are polling for the same data.
This redundancy not only saturates the API but also wastes valuable resources, leading to increased latency and a degraded user experience. As the load continues to scale, the backend becomes a bottleneck, so it was time to hit the drawing board.
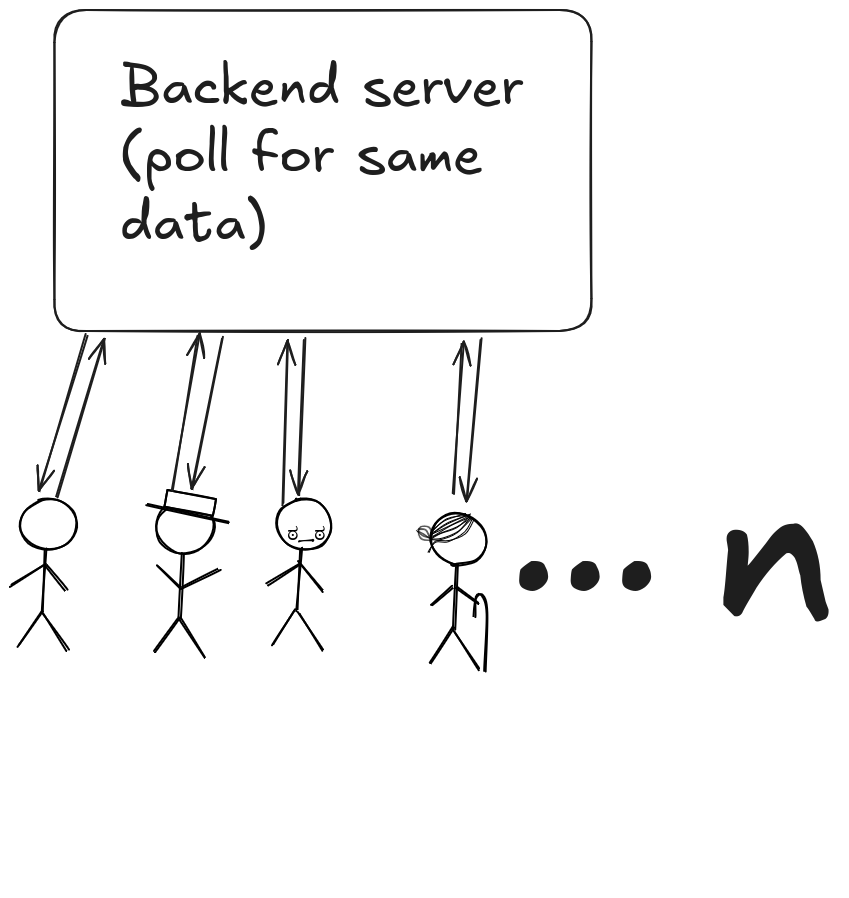 Redundant Client Polling to Backend
Redundant Client Polling to Backend
My Solution
Since the data that users needed to poll for was always going to be the same across all clients, I realized I could extract this redundancy and solve it architecturally. My goal was simple: make my backend receive a constant number of requests, independent of the number of users on the site. The solution I chose was both simple and effective: utilize pub/sub with a Redis caching layer and a dedicated polling microservice.
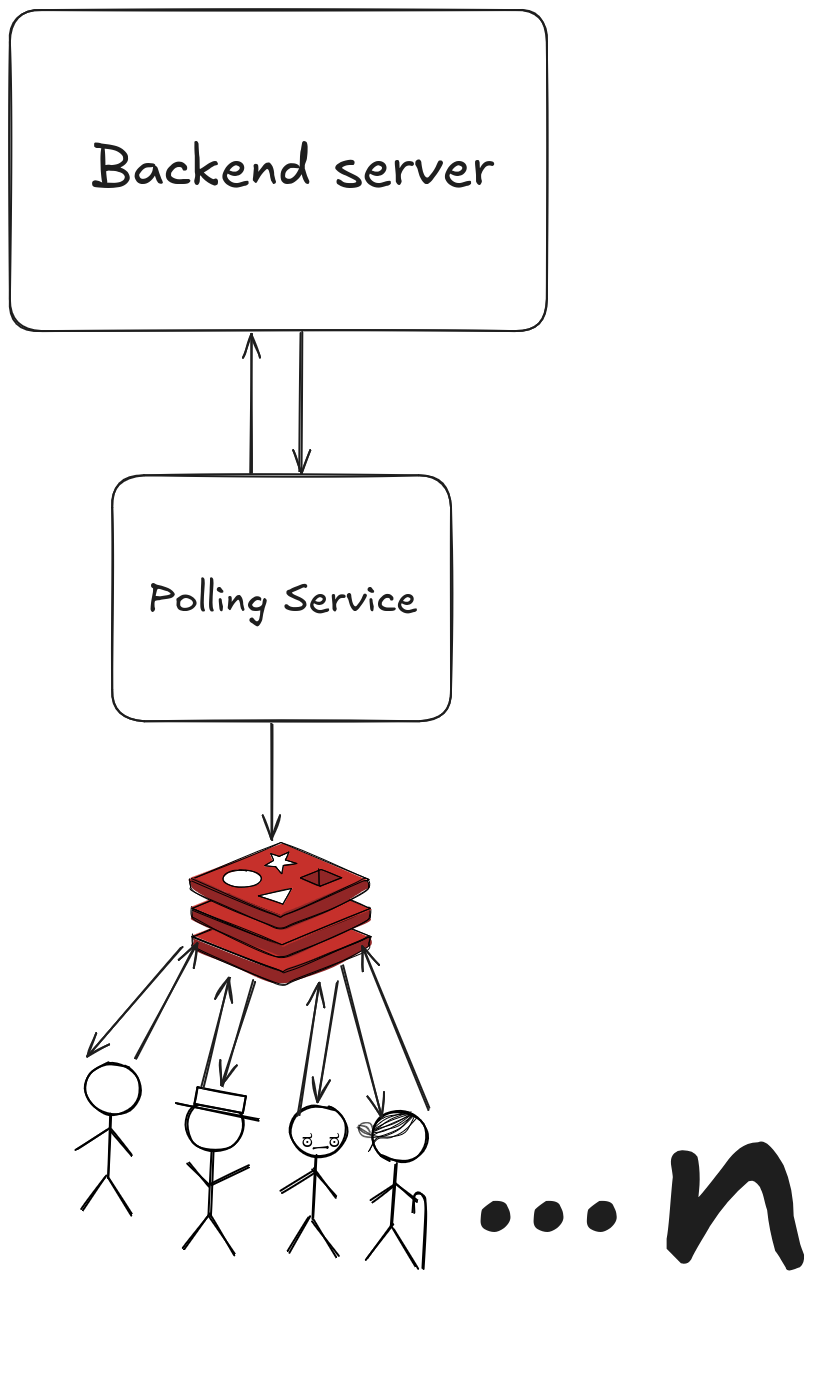 The improved architecture
The improved architecture
So how does this work? The polling microservice (I chose to write mine in Java) acts as a single, dedicated client that mirrors the original polling patterns. The Intermediate HTTP server(Implemented mine using Express.js) is there to retrieve the updates from redis and broker the messages to the clients.
Here's the flow:
- The microservice polls the backend - It makes the same API calls that individual users were making, but now there's only one client doing it
- Data gets cached in Redis - Each time it polls, the microservice writes the fresh data into Redis, overwriting the existing keys to ensure the data is always current
- Data gets published to Redis topic - Instead of hitting the backend directly, clients will now retrieve Server-Sent Events (SSE) brokered from the intermediate Http server.
Why Is This Better?
This approach dramatically reduces the load on our backend by:
- Eliminating redundant requests – Instead of 1,000 users making 1,200 requests/second to our backend, we now have just one microservice making ~1.2 requests/second. The backend load becomes constant and predictable, no longer scaling with user count.
- Leveraging Redis for ultra-fast caching – Redis is purpose-built to handle high-throughput read operations. While our
t2.microbackend would struggle with hundreds of concurrent requests, Redis can serve the same data to thousands of users with virtually no performance penalty. - Using Pub/Sub for instant client updates – Redis Pub/Sub lets us broadcast changes as soon as new data is available. Instead of clients having to poll repeatedly and check for differences, they’re now notified via Server-Sent Events (SSE) the moment something changes. This improves responsiveness while further reducing client-server chatter.
- Maintaining data freshness – The polling microservice keeps Redis updated with the latest data at the same frequency clients expect. From the user’s perspective, everything still feels real-time.
The Role of the Intermediate HTTP Server
The intermediate HTTP server plays a crucial role in the new architecture by acting as a broker between the clients and the Redis cache. While Redis is excellent for fast data storage and Pub/Sub messaging, it isn't designed to serve client-facing HTTP connections directly, especially for technologies like Server-Sent Events (SSE). The HTTP server fills this gap by maintaining persistent SSE connections with clients, listening to Redis Pub/Sub channels for updates, and streaming those updates to connected clients in real time. This separation of concerns ensures that Redis remains focused on high-performance data handling, while the HTTP server efficiently manages the client communication layer, handling connection lifecycles, reconnections, authentication, and delivery logic. Thus, the HTTP server is essential for bridging backend data and client-facing real-time delivery in a scalable and secure way
Why Bother Caching If We're Using Pub/Sub?
Caching results in Redis remains essential for two key reasons.
- First, it ensures that when a client initially connects, they can be shown the most recent data immediately. Without this cache, the client would have to wait until the next published update to see any content, resulting in a poor user experience. By storing the latest data in Redis, the system guarantees that there's always something to display as soon as a client connects, even before a new event is published.
- Second, caching helps mitigate the impact of failures in the polling service. If the polling microservice goes down temporarily, Redis still holds the last known good state of the data. While it may become slightly outdated, the client can continue functioning and displaying useful information until the poller comes back online. This added layer of resilience helps maintain service continuity and improves fault tolerance across the system.
Potential Trade-off
While the redesigned architecture significantly reduces backend load and improves scalability, it introduces a fair amount of complexity and operational overhead. By adding Redis, a polling microservice, and an intermediate HTTP server, you’ve moved from a relatively straightforward setup to a distributed system with multiple components that must be deployed, monitored, and maintained. Each service now has its own lifecycle, requiring CI/CD pipelines, logging, alerting, and health checks, which increases the engineering burden. This added complexity also affects troubleshooting—issues that were once confined to a single backend now may require inspecting Redis state, microservice logs, or SSE connection health to trace a problem.
Other Approaches
Event Streaming
I am currently experimenting with Apache Kafka to get around the limitation of not being able to establish WebSocket connections with my Upstash Redis database. This approach seems promising - I am able to push my data to Kafka topics and getting real-time updates to clients. However, I ran into two roadblocks:
- Initial State Problem: On initial connection to the Kafka topics, the data is null, meaning users don't see any content when they first load the site. This is a mandatory functionality for my app, users need to see the current state immediately, not wait for the next update to come through.
- Complex Data Formatting: My backend serves complex JSON data structures, and I'm encountering issues getting this formatted data into Kafka topics and then reliably relaying it to the frontend in a usable format.
I'm optimistic about its long-term viability, although it still needs work before it can fully replace my current setup.
Polling Directly from Redis Cache
The simplest approach I tried actually my initial attempt at optimization was to keep the polling strategy in place, but have clients poll the Redis cache instead of the backend API. This seemed like a smart move at the time: Redis is incredibly fast, capable of handling millions of reads per second, and offloading traffic from my limited backend server was a top priority. Initially, this approach worked well. Clients were able to retrieve data quickly, and the backend experienced significantly less strain. However, the solution introduced a new problem: excessive I/O and cost. Since all clients were still polling independently at regular intervals, the total number of requests hitting my Upstash Redis database grew rapidly. Unlike local in-memory caches or self-hosted Redis, Upstash charges based on usage, so each redundant poll from a client became a cost multiplier. Despite Redis's ability to handle the read volume technically, the financial and network overhead of having every client independently query the same data made this approach unsustainable at scale. It became clear that simply shifting the polling burden from one layer to another wasn't enough—I needed a more intelligent, centralized, and event-driven way to manage real-time data delivery.
Final Thoughts
What started as a simple polling setup gradually evolved into a full-blown architectural challenge one that pushed me to rethink how real-time data should be delivered at scale. By introducing a dedicated polling microservice, a Redis caching layer, and a Pub/Sub model, I was able to reduce backend API load by over 90%, all while improving responsiveness and reliability.
Of course, this architecture isn’t a one-size-fits-all solution. It introduces additional components and operational overhead, so whether it’s the right approach for you depends on your specific constraints and goals. But for my use case, it’s been a stable, scalable, and maintainable system — and it’s given me confidence that my app can grow without the backend becoming a bottleneck.
If you're dealing with redundant API calls, performance bottlenecks, or growing concurrency issues, don't overlook the power of intelligent caching and architectural simplification. Sometimes, the most effective solutions aren't the most complex — they’re the ones that reduce friction and let each part of the system do what it does best.
I’d love to hear how others are solving similar challenges feel free to reach out either on X or LinkedIn! I'd love to hear from you.